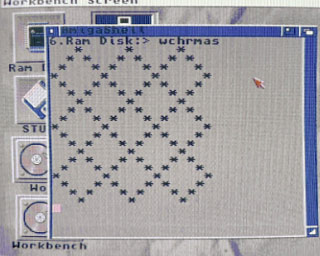
wchrmas pattern
My contribution to the Vintage Computing Christmas Challenge 2023. The goal is to recreate a certain pattern using any programming language and computer platform you like, while getting the code as small as possible. This year it’s a pattern made of diagonal lines, a christmesh. :)

If you’re into this kind of sizecoding contest, check out all the challenges:
- 2021: Christmas tree
- Common solution strategy: include row width table
- Discussion on sizecoding.net
- Results on demozoo.org
- 2022: Christmas star
- Treat the star as a combination of rotated triangles, and other strategies
- Discussion on sizecoding.net
- Results on demozoo.org
- 2023: Christmas diamonds
- Common strategies: counter-based, substrings, parametric formula, mirroring, many others
- No discussion on sizecoding.net yet
- Results on demozoo.org
It’s reassuring to see that better solutions are usually still being found after the deadline. In fact, I stumbled upon a way to save 2 bytes on my own code when writing this article… (see end of page)
Erratum: Haha, I got the function name all wrong! The name-giving BCPL call is wrch (see TRIPOS source), not wchr! Well, it’s released now…
My code
I chose Amiga and assembly, of course, and tried to see how small I could go. The shortest solution will probably be made in C64 or ZX80 assembly again, but maybe Amiga can play along in the top 30? I’m excited to find out!
Update: Top 30 turned out to be… ambitious! There was a flood of fantastic entries, and this landed on a shared 61st place. The smallest one by Art-top in Z80 assembly used only 23 bytes! It was nice to see several other Amiga entries, and also nice to see mine was the shortest. :)
Still, this challenge is about the fun, and I had a lot of it when watching the results! I especially liked atsampson’s Amiga solution which used bitmap graphics and a clever copperlist. Truly an Amiga-appropriate approach!
Here’s what I came up with after a week of byte crunching: 60 bytes
Update: For the after-compo category, I’m down to 56 bytes. :)
moveq #4,d6 ; counter A
moveq #4,d7 ; counter B
.loop moveq #32,d1 ; d1=' '
bsr.b .mod ; update A, maybe set d1='*'
bsr.b .mod ; update B, maybe set d1='*'
add.w #1724,d0 ; line-length counter
bvc.b .puts ; line not done? print d1
moveq #0,d0 ; reset line-length
addq.w #1,d6 ; adjust A for next line
subq.w #3,d7 ; adjust B for next line
moveq #10,d1 ; d1='\n'
.puts movem.l d0-a6,-(a7) ; save registers
moveq #32,d0 ; BCPL global area
move.l 224(a2),a4 ; BCPL offset of "wchr"
jsr (a5) ; BCPL call, prints d1
movem.l (a7)+,d0-a6 ; restore registers
bra.b .loop ; repeat
.mod subq.w #1,d6 ; decrement counter
bge.b .norst ; counter >= 0? no wrap
addq.w #6,d6 ; wrap counter
.norst bne.b .nostr ; counter != 0? no star
moveq #42,d1 ; set d1='*'
addq.b #2,d4 ; stars += 2
.done bcs.b done ; stars > 255? loop forever
.nostr exg d6,d7 ; swap counters A and B
rts
What this does:
- Use two counters, one for each direction: / and \
- Print one character at a time in a loop
- Start with
' 'as the next character (space) - Update both counters
- If the counter fulfills a condition, set the next character to
'*' - If this was the nth star, end program
- If the counter fulfills a condition, set the next character to
- If this is the nth character of a line,
- set the next character to
'\n'(newline) and - adjust the counters
- set the next character to
- Print the next character
- Start with
More specifically, the counters are decreased by 1 in each iteration and restart at 5 once they get below 0. In other words, each counter goes through the values 5, 4, 3, 2, 1, 0, 5, 4, 3, … and so on. Whenever a counter has a value of 0, an asterisk/star is printed. After every line, the counters are adjusted differently, so one pattern moves to the left and the other to the right:
Counter A Counter B Output -------------------- -------------------- ------------------- 32105432105432105432 32105432105432105432 * * * 21054321054321054321 43210543210543210543 * * * * * * 10543210543210543210 54321054321054321054 * * * * * * 05432105432105432105 05432105432105432105 * * * * 54321054321054321054 10543210543210543210 * * * * * * 43210543210543210543 21054321054321054321 * * * * * * 32105432105432105432 32105432105432105432 * * * 21054321054321054321 43210543210543210543 * * * * * * 10543210543210543210 54321054321054321054 * * * * * * 05432105432105432105 05432105432105432105 * * * * 54321054321054321054 10543210543210543210 * * * * * * 43210543210543210543 21054321054321054321 * * * * * * 32105432105432105432 32105432105432105432 * * * 21054321054321054321 43210543210543210543 * * * * * * 10543210543210543210 54321054321054321054 * * * * * * 05432105432105432105 05432105432105432105 * * * * 54321054321054321054 10543210543210543210 * * * * * * 43210543210543210543 21054321054321054321 * * * * * * 32105432105432105432 32105432105432105432 * * *
Note that the last counter state of a line is discarded and the output character is overwritten with a newline character.
This looks pretty straight forward, but is it the best approach? I’m not sure! Maybe there’s a clever way to calculate the “star or not” decision with a closed formula, without the need for two counters.
Tricks
Well, “tricks” might be far-fetched. These are some of the space-saving techniques used in the code:
BCPL FTW
To shorten the code, I’m using BCPL calls again. In
hypotrain I used writeoutput, and
now it’s time for wchr to shine!
What is BCPL? The programming language TRIPOS was written in, the original DOS component of the Amiga’s operating system. It’s kind of weird and awkward to use (see How to do a Forbid() in BCPL), but it provides shorter methods to do certain I/O tasks.
To print a single character to STDOUT we can write:
moveq #42,d1 ; d1: char '*'
moveq #32,d0 ; d0: size of "global area"
move.l 224(a2),a4 ; a4: address of "wchr"
jsr (a5) ; BCPL call function
Compare this to the amount of code and data when using dos.library:
move.l 4.w,a6
lea dosname(pc),a1
jsr -408(a6) ; OldOpenLibrary(a1:name)
move.l d0,a6 ; dosbase
jsr -60(a6) ; Output()
move.l d0,d1 ; stdout filehandle
moveq #42,d2 ; char '*'
jsr -312(a6) ; FPutC(d1:fh, d2:char)
...
dosname:
dc.b 'dos.library',0
The whole BCPL call to wchr is shorter than the “dos.library” string alone!
(Yes, there are shortcuts to get to the DOS library base, but they also take up space and we would still need to obtain the STDOUT file handle.)
Sadly, we need to spend some bytes of those savings again to save and restore all registers – BCPL calls will usually trash some registers, and there is no single fixed register that will be left alone across Kickstart versions!
- Kickstart 1.2 and 1.3
- d5/d6/d7 untouched
- But printing a newline will trash d5/d7
- Kickstart 2.0 and 3.1
- d2/d3/d4 untouched
The save/restore instructions eat up 8 bytes and we get:
.puts movem.l d0-a6,-(a7) ; 48e7 fffe
moveq #32,d0 ; 7020
move.l 224(a2),a4 ; 286a 00e0
jsr (a5) ; 4e95
movem.l (a7)+,d0-a6 ; 4cdf 7fff
16 bytes of code to print a single character – not great (compared to platforms where this is a single int or jsr instruction), not terrible (compared to using dos.library).
Conditions without compare
The code needs to check certain conditions:
- Is the current line full?
- Is it time to reset a counter?
- Is it time to output a
*? - Is it time to end the program?
All these conditions have been written to act on the arithmetic result flags of an addition or subtraction alone, avoiding comparisons with an explicit target value. Example:
addq #1,d0
cmp.w #20,d0
blt.b .puts ; less than 20 characters?
Can be rewritten as:
add.w #1724,d0
bvc.b .puts ; addition w/o overflow?
Using the fact that the bvc test (branch when overflow clear) will become false at the 20th iteration:
1724 × 19 = 32756 = $7ff4 hex– overflow flag clear1724 × 20 = 34480 = $86b0 hex– overflow flag set:
34480 cannot be represented as a signed word, $86b0.w is -31056
Similarily, the end-of-program endless loop is triggered like this:
addq.b #2,d4 .done bcs.b done
As a byte, d4 + 2 will cause the carry flag to be set once the 128th star is about to be written (254 + 2 = 256 cannot be represented as a byte).
Initial register contents
When an Amiga executable is run, d0 and d4 contain the value 1 as a longword (as long as the program is run without command line arguments). These values are used as the line-length counter (d0) and as the total-stars counter (d4).
Of course, we also assume the BCPL environment to be present in a1, a2, a5, and a6.
More stars than meet the eye
The overall “end program” condition (i.e. loop forever) is not triggered exactly when all 96 stars have been drawn, but a little later.
So why does the output still end cleanly with the last line of
the desired pattern – and not with a half-finished line? Internally,
a partial line is indeed being output via wchr, but it
is not printed because the output is buffered and only flushed (i.e. printed)
when a newline character is encountered. The endless loop that ends
the program is encountered before that, somewhere during the last,
unprinted line.
Discarded tricks and dead-ends
- Use a 19-character wide window
- ANSI escape sequence:
‹CSI›19u - Output would wrap automatically
- No need for newline characters
- But no savings either, still need to react on line ends so that one of the patterns moves to the left
- ANSI escape sequence:
- Calculate the modulo
- Instead of wrapping the counters manually from -1 to 5
- Calculate “print a star” as “counter modulo 6 == x”
- In assembly language:
divu #6,d6 ; lower word: d6 / 6 ; upper word: d6 % 6 (remainder) swap d6 cmp.w #x,d6 ; or tst.w d6 - Costly: need to save the counter because its original value is destroyed
- Using the BCPL
modmethod didn’t align well with register usage
- Two counters in one longword
- Tried to keep total and per-line character count in one longword
- Tried to put both counters as words in one longword, swapping between them
- moveq/addq versions were shorter in both cases, especially if an extra tst.w was needed
- Re-use space character
- There are two very similar constant initializations:
moveq #32,d1 ; ' ' space character moveq #32,d0 ; size of BCPL global area (required)
- Didn’t find a way to reduce them
- There are two very similar constant initializations:
- Alternative space
- We could use
$a0(non-breaking space) instead of$20as the space character:moveq #-96,d1 ; -96 = $ffffffa0 ; wchr only prints byte $a0 - Idea was to re-use the value of -96 somewhere else
- We could use
- Reordering code blocks
- Are the two
bsr.b .modcalls necessary? - Can we combine .puts and .mod in a clever way, saving on branches/returns?
- Are the two
- Pattern data
- Lose the counters altogether
- Find a compact representation of the pattern instead
- Self-modifying code
- We can request to be run in chip RAM, so this should be compatible (as code in chip RAM is not cached IIRC)
- Not explored
Final file
- OS overhead
Amiga executable hunk structure (36 bytes)
- Code
68000 machine code (60 bytes)
00: 0000 03f3 0000 0000 0000 0001 0000 0000 ................ 10: 0000 0000 0000 000f 0000 03e9 0000 000f ................ 20: 7c04 7e04 7220 6122 6120 d07c 06bc 6808 |.~.r a"a .|..h. 30: 7000 5246 5747 720a 48e7 fffe 7020 286a p.RFWGr.H...p (j 40: 00e0 4e95 4cdf 7fff 60da 5346 6c02 5c46 ..N.L...`.SFl.\F 50: 6606 722a 5404 65fe cd47 4e75 0000 03f2 f.r*T.e..GNu....
Assembled code
moveq #4,d6 ; 7c04
moveq #4,d7 ; 7e04
.loop moveq #32,d1 ; 7220
bsr.b .mod ; 6122
bsr.b .mod ; 6120
add.w #1724,d0 ; d07c 06bc
bvc.b .puts ; 6808
moveq #0,d0 ; 7000
addq.w #1,d6 ; 5246
subq.w #3,d7 ; 5747
moveq #10,d1 ; 720a
.puts movem.l d0-a6,-(a7) ; 48e7 fffe
moveq #32,d0 ; 7020
move.l 224(a2),a4 ; 286a 00e0
jsr (a5) ; 4e95
movem.l (a7)+,d0-a6 ; 4cdf 7fff
bra.b .loop ; 60da
.mod subq.w #1,d6 ; 5346
bge.b .norst ; 6c02
addq.w #6,d6 ; 5c46
.norst bne.b .nostr ; 6606
moveq #42,d1 ; 722a
addq.b #2,d4 ; 5404
.done bcs.b done ; 65fe
.nostr exg d6,d7 ; cd47
rts ; 4e75
Downloads


Bonus: Spot the waste!
As mentioned earlier, I found another size optimization when writing this. Can you see an opportunity to save 2 bytes in the code above? Hint: It’s in the math…
After-deadline optimization #1
The line-length check is not optimal; we do not need to reset the counter to 0 if we check the carry flag (unsigned) instead of the overflow flag (signed)! We can just keep adding to d0, and it will wrap from some $fxxx value to $0xxx exactly when a newline is due.
With the right increment value and status flag test, we are down to 58 bytes:
moveq #4,d6 ; 7c04
moveq #4,d7 ; 7e04
.loop moveq #32,d1 ; 72a0
bsr.b .mod ; 6120
bsr.b .mod ; 611e
add.w #1724,d0 ; d07c 06bc
bvc.b .puts ; 6808
moveq #0,d0 ; 7000
add.w #3284,d0 ; d07c 0cd4
bcc.b .puts ; 6406
addq.w #1,d6 ; 5246
subq.w #3,d7 ; 5747
moveq #10,d1 ; 720a
.puts movem.l d0-a6,-(a7) ; 48e7 fffe
moveq #32,d0 ; 7020
move.l 224(a2),a4 ; 286a 00e0
jsr (a5) ; 4e95
movem.l (a7)+,d0-a6 ; 4cdf 7fff
bra.b .loop ; 60dc
.mod subq.w #1,d6 ; 5346
bge.b .norst ; 6c02
addq.w #6,d6 ; 5c46
.norst bne.b .nostr ; 6606
moveq #42,d1 ; 722a
addq.b #2,d4 ; 5404
.done bcs.b done ; 65fe
.nostr exg d6,d7 ; cd47
rts ; 4e75
After-deadline (non-)optimization #2
I also tried a closed-formula approach, calculating (x*x-y*y)%6 directly. That was taken from KeyJ’s Python solution (see below). I could only bring that down to 66 bytes, but maybe my sizecoding foo is exhausted for the year…
moveq #19-1,d7
.rows moveq #19-1,d6
.cols moveq #' ',d1
move.l d7,d5
mulu d5,d5 ; y*y
move.l d6,d4
mulu d4,d4 ; x*x
sub.l d5,d4 ; (x*x-y*y)
bge.b .ispos
neg.l d4 ; remainder -> modulo
.ispos divu #6,d4
swap d4
subq.w #3,d4 ; shorter than cmp.w
bne.b .nost
moveq #'*',d1 ; (x*x-y*y) % 6 == 3
.nost bsr.b .puts
dbf d6,.cols
moveq #10,d1
bsr.b .puts
dbf d7,.rows
rts
.puts movem.l d0-a6,-(a7)
moveq #32,d0
move.l 224(a2),a4
jsr (a5)
movem.l (a7)+,d0-a6
rts
After-deadline optimization #3
After some pondering, I realized that I could, indeed, lose the two bsr.b .mod calls!
Idea:
- Inline the
.modcode - Loop twice over that
The “loop twice” portion contains the optimization. A naïve solution might be:
moveq #1,d3
.mod (.mod code here)
subq #1,d3
beq.b .mod
But that isn’t shorter than before. Also, there is no register that conveniently holds a constant value in each execution that I could use.
Instead, I use the fact that d0 always holds a positive longword throughout the program. To have a loop with two executions, d0 is negated and a “is d0 negative” test is used for the loop. This way, I have abused the is-negative status as a loop counter, and d0 is restored to its original value afterwards.
Code size is 56 bytes now, yeah!
moveq #4,d6
moveq #4,d7
.loop moveq #32,d1
bsr.b .mod
bsr.b .mod
.mod subq.w #1,d6
bge.b .norst
addq #6,d6
.norst bne.b .nostr
moveq #42,d1
addq.b #2,d4
.done bcs.b .done
.nostr exg d6,d7
rts
neg.l d0
blt.b .mod
add.w #3284,d0
bcc.b .puts
addq.w #1,d6
subq.w #3,d7
moveq #10,d1
.puts movem.l d0-a6,-(a7)
moveq #32,d0
move.l 224(a2),a4
jsr (a5)
movem.l (a7)+,d0-a6
bra.b .loop
A peek at the other side
C64 madness
Some time after the deadline, Serato posted a 25-byte solution for the C64. (Meanwhile it’s down to 23 bytes, I’ve heard.) Curious, and because I was waiting for the YouTube premiere of the result video anyway, I wanted to know how it works.
Unfamiliar with 6502 coding, I had to look up some opcodes, regular ones and “illegal” ones, to try to make sense of the code. But to no avail… I only started to get a grasp of the code when I had visualized a bit:
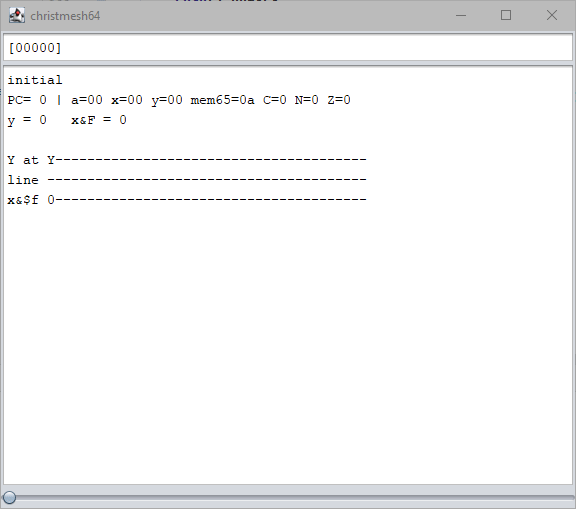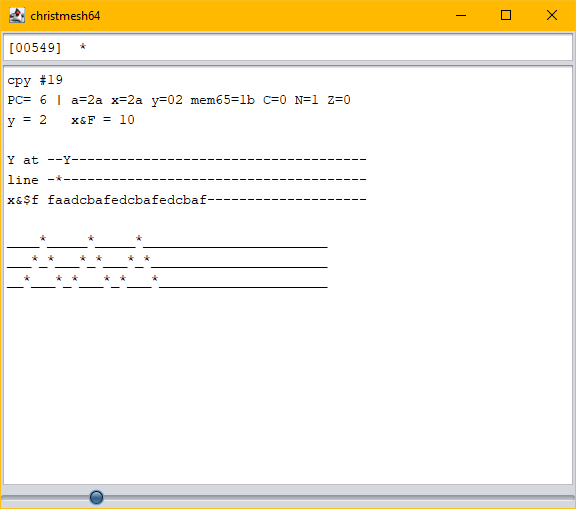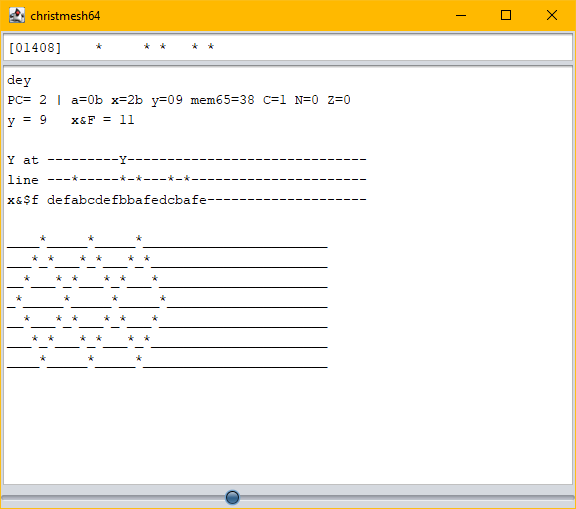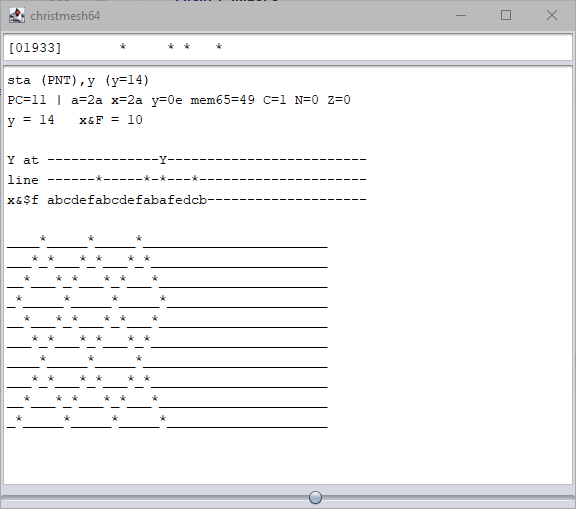
Nifty! But not really transferrable to my approach (as I don’t have a line buffer, to begin with). Would have been interesting to shave off some more bytes after the deadline, for funzies.
Closed-formula approaches
In Xeleh’s Amiga entry (at 68 bytes) the “star or not” decision is calculated directly from the current position. Given column and row from 0 to 18, you get:
(x+y+3)%6 == 0 || (x-y+21)%6 == 0 → print a star
When plotted, this looks similar to my “running” numbers that my approach gets from updating two counters on the fly:
(x+y+3)%6 (x-y+21)%6 ------------------- ------------------- 3450123450123450123 3450123450123450123 4501234501234501234 2345012345012345012 5012345012345012345 1234501234501234501 0123450123450123450 0123450123450123450 1234501234501234501 5012345012345012345 2345012345012345012 4501234501234501234 3450123450123450123 3450123450123450123 4501234501234501234 2345012345012345012 5012345012345012345 1234501234501234501 0123450123450123450 0123450123450123450 1234501234501234501 5012345012345012345 2345012345012345012 4501234501234501234 3450123450123450123 3450123450123450123 4501234501234501234 2345012345012345012 5012345012345012345 1234501234501234501 0123450123450123450 0123450123450123450 1234501234501234501 5012345012345012345 2345012345012345012 4501234501234501234 3450123450123450123 3450123450123450123
KeyJ’s Python oneliner (72 bytes for Python 2) uses:
(x*x-y*y)%6 < 1 → print a star
This assumes row values from 0 to 19 and column values from 3 to 21 and gives:
3 4 1 0 1 4 3 4 1 0 1 4 3 4 1 0 1 4 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 1 4 3 4 1 0 1 4 3 4 1 0 1 4 3 4 1 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 4 1 0 1 4 3 4 1 0 1 4 3 4 1 0 1 4 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 1 4 3 4 1 0 1 4 3 4 1 0 1 4 3 4 1 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 4 1 0 1 4 3 4 1 0 1 4 3 4 1 0 1 4 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 1 4 3 4 1 0 1 4 3 4 1 0 1 4 3 4 1 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 2 3 0 5 0 3 2 3 0 5 0 3 2 3 0 5 0 3 2 3 4 1 0 1 4 3 4 1 0 1 4 3 4 1 0 1 4 3
Hmm, looking at the code and the “<1” check… (linebreak added for formatting)
for y in range(19):
print''.join(' *'[(x*x-y*y)%6<1]for x in range(3,22))
Couldn’t you use [(x*x-y*y)%6==3]for x in range(19) and save a byte? :)
Logo ❤
It was lovely to see three Logo entries, all in turtle graphics! fieserWolF started off in a web-based Logo environment, sporting hand-drawn, errm, flap-drawn stars:

Verz’s wild entry runs on Terrapin Logo for the C64 and you can watch the turtle meticulously draw all the asterisks if you have the patience:

Just neat!