Temba, seine Arme weit!
A 512 byte intro made for Nordlicht 2025. Also, a tribute to the mother of all (German) fan-subs: “Sinnlos im Weltraum” :)
Edit: Source code linked below.
WTF is “Sinnlos im Weltraum”? A bunch of dubbed Star Trek TNG episodes made in the late 1990s, all in a weird German dialect, putting a spin on the story lines and each of the characters: Picard becomes a grumpy choleric who constantly threatens to beat up everyone, Riker is a child-like doofus, Geordi is utterly confused all the time, etc. Black coffee plays a big role, as do the self-made sound effects and music. SiW gained a bit of a cult following – it’s even got its own Wikipedia page!
The intro shows Dathon, the Tamarian captain from the TNG episode “Darmok”. In the German SiW version, he has a very unique way of talking and says “Joooaaaahh” a lot – that’s also in the intro! :)

Image copyright for the Tamarians on the left: Paramount Global, used in low resolution under “fair use” terms for educational purposes.
Why the “Sinnlos im Weltraum” hommage? Because the party website was sci-fi themed (galactic quest, futuristic neon adventure, etc.), and I have a habit of adapting the party theme in 512 bytes!
It speaks!
Well, at least it does the “Joooaaahh” sound from the SiW episode. This was the main idea for the intro: Use the new speech synthesis method I stumbled upon to produce vowel sounds, then let them blend into each other.
The implementation is simple: Each vowel sound is the sum of the first n harmonic waves of the base frequency, each multiplied by a factor, and those factors shape the sound into an “eeeh” or “ooh”.
For some background, pseudocode, and actual code, see:
- Speech shenanigans (blog post)
- Ugly speech toy (interactive tool)
The important thing is that this approach seemed like a good fit for a 512 byte production. To prototype the “Jooaah” sound, I hacked up the speech tool to include an FFT display of a waveform that I could overlay onto the harmonic factor knobs, reconstructing the original “Jooaah” sound one vowel at a time:
After that, I coded the speech synth in 68000 assembly, with the help of another prototyping tool. This tool runs the assembly code and plays back the generated wave form immediately.
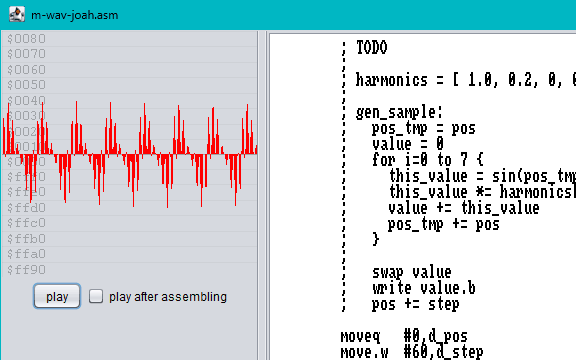
; @factors = points to 8 harmonic factors
; @wav = points to the waveform we're building
moveq #0,@smp ; initial sample value := 0
move.l @sinpos,@pos ; copy global sine position
rept 8
move.l @pos,@tmp ; look up sine_table[sinpos]
swap @tmp
and.w #1024-2,@tmp ; sine table has 512 words
move.w (@sintab,@tmp.w),@tmp ; sine value
move.w (@factors)+,@val ; factor for this harmonic wave
addq.w #2,@factors ; skip fractional bits
muls @val,@tmp ; sinval *= factor
add.l @tmp,@smp ; sample += sinval
add.l @sinpos,@pos ; next harmonic
endr
swap @smp ; sample: $007fff00 --> $007f
move.b @smp,(@wav)+ ; output sample byte
All values use a 16+16 bit fixed floating point format, i. e. the upper 16 bit word is the integer amount and the lower 16 bits represent the fractional part. (The 68000 CPU doesn’t support “real” floating point arithmetic.)
$00010000 = %00000000000000010000000000000000 = 1 $00018000 = %00000000000000011000000000000000 = 1.5 $0003243f = %00000000000000110010010000111111 = 3.14159 etc.
This way, we can fine-tune the base frequency and interpolate the harmonic factors very smoothly.
Originally I planned to do the sound synthesis in realtime, writing the audio data with the CPU, but all those multiplications were too slow for an acceptable sample rate. Instead, there’s a single 64 KB buffer now that gets repeated throughout the intro.
I like big pixels and I cannot lie
The second thing I built for the intro: A low resolution, but recognizable Tamarian head! Cute or dorky, if possible…
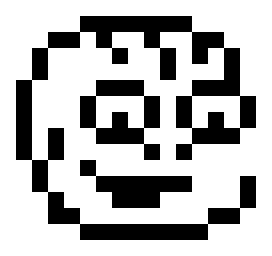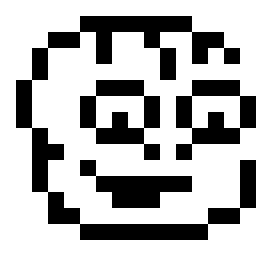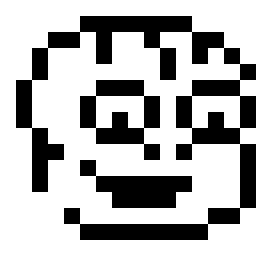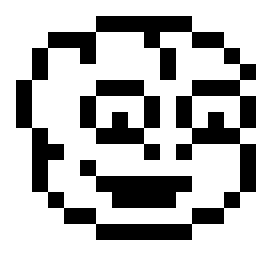
After several revisions, I went for a resolution of 15×14 pixels, stored as 14 rows of 16 bytes each. In other words: The pixels are already horizontally stretched, with each fat pixel taking up one byte = eight pixels.
__ = 0 XX = $ff dc.b __,__,__,__,__,XX,XX,XX,XX,XX,XX,__,__,__,__,__ dc.b __,__,XX,XX,XX,__,__,__,XX,__,__,XX,XX,__,__,__ dc.b __,XX,__,__,XX,__,__,__,__,XX,__,__,__,XX,__,__ dc.b __,XX,__,__,__,__,__,__,__,XX,__,__,__,__,XX,__ dc.b XX,__,__,__,__,XX,XX,XX,__,__,__,XX,XX,XX,__,__ dc.b XX,__,__,__,XX,__,__,__,XX,__,XX,__,__,__,XX,__ dc.b XX,__,__,__,XX,__,XX,__,XX,__,XX,__,XX,__,XX,__ dc.b __,XX,__,__,__,XX,XX,XX,__,__,__,XX,XX,XX,__,__ dc.b __,XX,XX,__,__,__,__,__,XX,__,XX,__,__,__,XX,__ dc.b __,XX,__,__,XX,__,__,__,__,__,__,__,__,__,XX,__ dc.b __,XX,__,__,__,XX,XX,XX,XX,XX,XX,__,__,__,XX,__ dc.b __,__,XX,__,__,__,__,__,__,__,__,__,__,XX,__,__ dc.b __,__,__,XX,XX,__,__,__,__,__,__,XX,XX,__,__,__ dc.b __,__,__,__,__,XX,XX,XX,XX,XX,XX,__,__,__,__,__
The vertical stretch is done by the copperlist: Display a new line, then display that same line for the next seven display rows, repeat. In each line, we wait for the right-most display position, ignoring (masking) the Y position, and tell the display DMA to either continue with the next line or skip back 16 bytes. This way, we get a nice, repetitive chunk of Copper wait commands:
dc.w $0108,-16 ; repeat first line (blank) dc.w $8101,$fffe ; top y position ($81..$f9) dc.w $80df,$00fe,$0108,0 ; show new line ( 0 = continue bitmap) dc.w $80df,$00fe,$0108,-16 ; repeat line (-16 = go back 16 bytes) dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,0 ; show new line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line dc.w $80df,$00fe,$0108,-16 ; repeat line etc.
“But all those repetitions and those fat pixels – don’t they use up a lot of space?” They do, but only before the compression!
Better compression
I fiddled a lot with the compression this time (again using ZX0 as the compression algorithm).
- I optimized the common 68000 decompression routine for ZX0 – it’s two bytes shorter now.
- I used a smaller ZX0 end marker for my data. This only saved two bits of control data, but sometimes this can save you a byte in the compressed payload!
- Less data: I removed in-between interpolation target steps as long as the resulting sound still sounded more-or-less the same.
- I saved another two bytes by doing something very dirty: The decompression
target address is taken from the opcodes of the depacker code itself.
Drawback: This will only work on 68000 CPUs where the upper 8 bits
of a 32-bit address are ignored.
lea $50000,a4;49f9 0005 0000move.l .opc(pc),a4 ; 287a 0032 ... .opc move.w d5,d6 ; 3c05 lsl.w #8,d6 ; e14e ; a4 now contains $3c05e14e which is treated ; like $005e14e on the 68000. 2 bytes saved! - Compression optimizations by analyzing the raw data. I wrote a tool to visualize
repeating data words and help me pick color values from existing binary values.
I found some reusable values this way, but it got tedious quickly…
- Random, mostly gut-driven compression optimizations: Flip the Tamarian head vertically, try out different opcodes for the same tasks, insert a chunk of zeroes somewhere. High dopamine levels possible when successful, but also high levels of “What exactly am I doing here?” :)
- As a final test to my sanity, I started playing around with random permutations. There are sections in the code where the order doesn’t matter for the result: Disable sprites first, then install the copperlist, or the other way around? But also data blocks and… well, nearly everything.
Trying out all possible combinations for a block of code quickly becomes a huge task. For nine lines, there are 9! = 362,880 different sequences to be tested, each with a cycle of “assemble, ZX0-compress, measure the number of bits”. Also, the results are often counterintuitive and brittle, heavily depending on all the other bits staying where they are.
That being said, this approach did help me save the last two bytes I needed when I was already on the train to Bremen. Through the power of brute-forcing, the intro now exits cleanly and restores the mouse pointer when done.
Compatibility
Having the intro exit cleanly is nice, but I would have loved to make everything more compatible and avoid unpacking into a fixed, unallocated memory region as well.
I had already found a way
to do that while saving two bytes in the decompress code, by using the
destination address as the start-of-data address: We can just
reverse the bytes of the ZX0 data and replace every
(a0)+ with -(a0). Starting from the same address,
the decompress code would read the ZX0 data backwards and write the decompression
result forwards.
lea .zx0(pc),a0;41fa 005c- source datamove.l .opc(pc),a1;227a 0034- absolute destination lea .zx0_end(pc),a0 ; 41fa 01d8 - source data move.l a0,a1 ; 2248 - destination = source pea (a1) ; 4851 .zx0_decompress: ... incbin meat.zx0.reversed .zx0_end: dx.b 1024*80 ; room for decompressed code and data
The dx.b at the end would reserve some BSS space via the
executable header without affecting the binary size.
Initially, the code got bigger after this change (we cannot hardcode the bitplane address in the Copper list anymore, and other little changes), but this still may have worked. I just ran out of time and patience to explore this further…
A final touch
As luck would have it, I drew the Tamarian’s mouth exactly in a way that I had four consecutive pixels as the bottom part, allowing for a primitive mouth animation:

In code, I could set these four pixels with a timer-based longword move:
moveq #-1,@q ; -1 = $ffffffff (mouth open)
add.w #$9f,@blink ; magic timer constant
blt.b .noblnk ; switch mouths when negative
moveq #0,@q ; 0 = $00000000 (mouth closed)
.noblnk
move.l @q,bitmap-12*16+6



